

それでは、ここで紹介します – ハードウェアの作成を支援したチームの 2 人の重要なメンバーとの、Xbox One アーキテクチャに関する Digital Foundry のディスカッションの完全な記録です。ここでは、約 1 時間に相当する非常に密度の高い技術的な話を見ていますが、その多くはこれまで見たことのないものです。
まず最初に、背景について少し説明します。この機会はどのようにして生まれたのでしょうか? 8月のGamescomでは、Microsoftが技術的な観点から自社のハードウェアについてどのように語るかについて、スタンスを調整しようとしていることが明らかになった。ほぼ確実にこれは、ソニーが PlayStation 4 向けに提供している同等の指標と比較して、全体的なスペックシートがあまり期待できるものではないことが原因であり、ゲーマーによる一部のスペックの解釈が Microsoft の解釈と完全に一致していないことは明らかでした。デザインを考え中。
しかし、今後のコンソール戦争に加えて、Xbox One が、同時アプリや複数の仮想マシンなどの要素を強化する野心的な技術を備え、まったく異なる哲学を念頭に置いて設計されていることは明らかです。全体的なバランスの議論は言うまでもなく、GPU コンピューティングにも非常に異なるアプローチがあります。この経験から、これが建築家たちが情熱を注いでおり、非常に伝えたかった物語であることは明らかでした。
そうは言っても、Microsoft には、コンソール アーキテクチャの構成に関する詳細なデータを共有してきた歴史があり、今年スタンフォード大学で開催された Hot Chips 25 でのプレゼンテーションでは、設計チームがシリコンについて詳しく話す用意があることが示されていました。ソニーが共有しようとしているものをある程度超えています。基本的にほとんどのことを説明してくれる仕様書があれば、PlayStation に関してはおそらく理解できるでしょう。
「マイクロソフトにとって、これはコアゲーマーが簡単に理解できない設計哲学を説明する機会でした。」
したがって、多くの人が疑問に思っているのは間違いなく、自由に流れる技術的な議論を検討しているのか、それとも PR 活動を検討しているのか、ということです。まあ、冗談は言わないでください。出版されるインタビューはすべて、インタビュー対象者に対する何らかの広報活動であり、それはマイクロソフト、ソニー、その他の誰と話す場合でも同様に当てはまります。おそらく、マーク・サーニーのインタビューで私たちがずっと失望したのは、彼がまだ他の場所で扱っていないことの多くを私たちに話させないつもりであることがすぐに明らかになったという事実でした。また、印象的なスペック、バランスのとれたラインナップ、そして驚異的によく管理された PR 戦略により、ソニーは非常に有利な立場にあり、少なくとも現時点では証明できるものは何もない、と言っても過言ではありません。
Microsoft の場合、状況は明らかに大きく異なります。これは、コアゲーマーがなかなか理解できない設計哲学を説明すると同時に、ゲーム コンソールの技術的能力が GPU やメモリのセットアップ – 皮肉なことに、これらは開発環境の品質と相まって、Xbox 360 が現世代コンソールの戦いの初期に優位に立つことを可能にしたまさに強みです。
それではディスカッションに入ります – おそらく Digital Foundry のこれまでで最も広範なハードウェア インタビューであり、必要な電話会議の紹介で始まります…
アンドリュー・グーセン
私の名前は Andrew Goossen です。Microsoft の技術員です。私は Xbox One のアーキテクトの 1 人でした。私は主にソフトウェア側に関与していますが、シリコンを完成させるためにニックと彼のチームと多くの作業を行ってきました。優れたバランスの取れたコンソールを設計するには、ソフトウェアとハードウェアのあらゆる側面を考慮する必要があります。重要なのは、この 2 つを組み合わせてパフォーマンスのバランスを実現することです。デザインについてお話させていただく機会ができて本当にうれしく思います。世の中には誤った情報が溢れており、理解していない人もたくさんいます。実際、私たちは自分たちのデザインを非常に誇りに思っています。私たちは非常にバランスが良く、非常に優れたパフォーマンスを持っていると考えており、生の ALU 以外のものを処理できる製品を持っています。他にも、レイテンシー、安定したフレームレート、タイトルがシステムなどによって中断されないことなど、その他にもかなり多くのデザイン面や要件があります。これは、私たちのシステム設計において広く浸透している進行中のテーマであることがわかります。
ニック・ベイカー
私は Nick Baker です。ハードウェア アーキテクチャ チームを管理しています。私たちは Xbox のほぼすべてのインスタンスに取り組んできました。私のチームは、利用可能なテクノロジーをすべて検討する責任を負っています。私たちはグラフィックスがどのような方向に向かうのかを常に考えています。それを理解するために、Andrew や DirectX チームとよく協力しています。私たちはハードウェア業界の他の多くの企業と良好な関係を築いており、実際、組織はハードウェアを策定し、特定の時点でどのようなテクノロジーが適切であるかを私たちに期待しています。次のコンソールがどのようなものになるかを検討し始めるとき、私たちは常にロードマップの先頭に立って、それがどこにあるのか、ゲーム開発者やソフトウェア テクノロジーと組み合わせてすべてを統合するのがどの程度適切であるかを理解しています。私はチームを管理しています。 Hot Chips でプレゼンテーションを行った John Sell をご存知かもしれません。彼は私の組織の 1 人です。さらに遡ると、2005 年の Hot Chips で Jeff Andrews と Xbox 360 のアーキテクチャについて発表しました。Andrew と同様に、私たちは少し前からこれを行ってきました。アンドリューは非常にうまく言いました。私たちは本当に高性能で電力効率の高いボックスを作りたかったのです。私たちはそれをモダンなリビングルームに合わせたものにしたかったのです。 AV について言えば、AV を出し入れしてエンターテイメントの中心となるメディア ハードウェアにできるのは当社だけです。
「私たちは、本当に高性能で電力効率の高いボックスを作りたかったのです。それを現代のリビングルームに合わせたものにしたかったのです。」

Digital Foundry
Xbox 360 の事後調査から得られたことは何ですか?また、それが Xbox One アーキテクチャで達成したいことをどのように形づくったのですか?
ニック・ベイカー
短い時間でここでお話しできるいくつかの側面をピックアップするのは困難です。重要なポイントの 1 つだと思います… 前回はいくつかの賭けをしましたが、その 1 つは、少数の高 IPC [クロックあたりの命令数] で電力を大量に消費する CPU を使用するのではなく、マルチプロセッサのアプローチを採用することでした。コア。私たちは、電力/パフォーマンス領域でより最適化されたコアを使用して、より並列性を高めるアプローチを採用しました。それはかなりうまくいきました…オーディオのオフロードなど、いくつかのことに気づきました。それに取り組む必要があったため、オーディオ ブロックに投資しました。私たちは最初から単一チップを使用し、すべてをできるだけメモリに近づけたいと考えていました。 CPU と GPU の両方で、すべてに低遅延と高帯域幅を提供することが重要な信念でした。
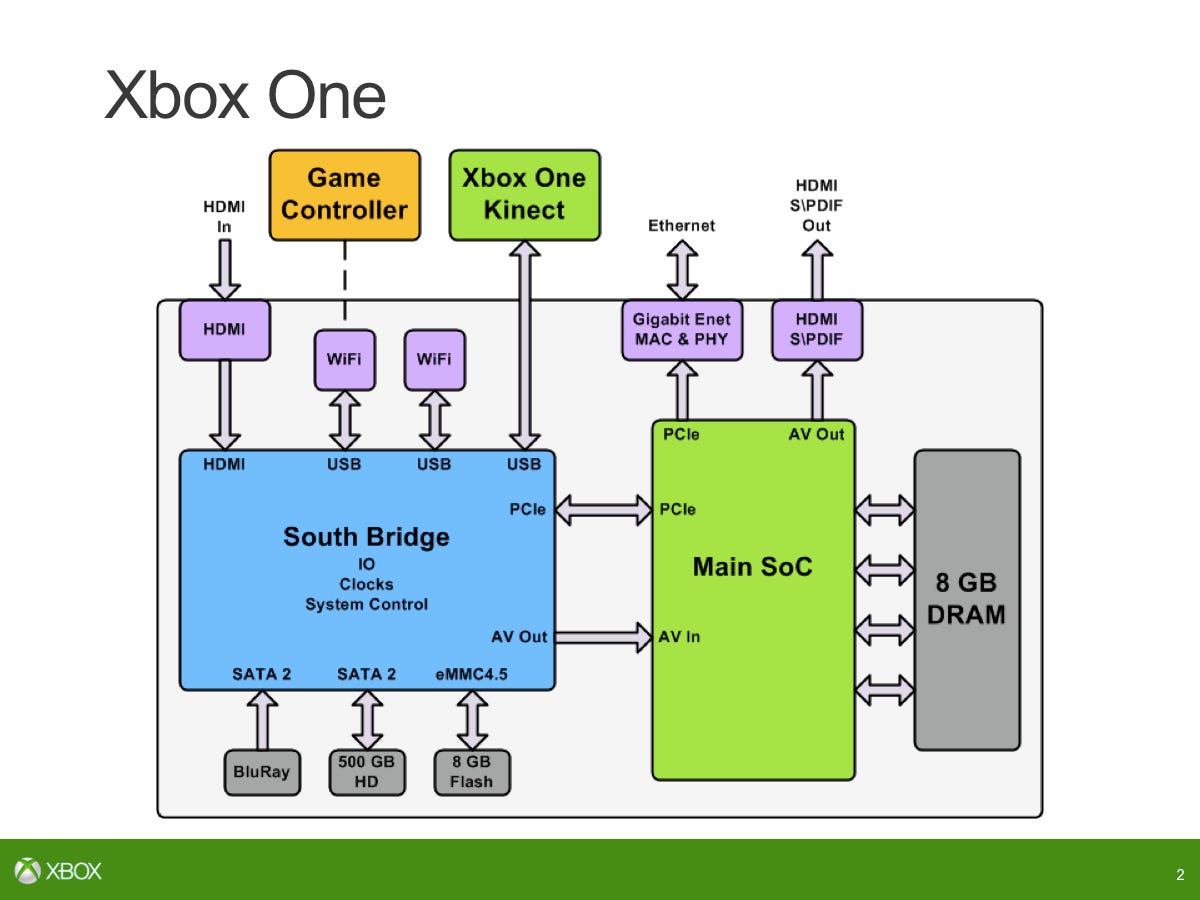
私たちが対処しなければならないいくつかの明らかな問題 – メモリの新しい構成、実際には CPU から GPU にポインターを渡すことができなかったので、GPGPU のコンピューティング シェーダーに向けて、それに対処したいと本当に考えていました。圧縮、私たちはこれに多大な投資を行ってきたため、多くの圧縮を処理するいくつかの Move エンジンが使用されています…その仕組みについては、GPU の機能に重点が置かれています。そして実際に、タイトルの互換性に影響を与えずにシステム サービスを時間の経過とともに拡張できるようにするにはどうすればよいでしょうか。この世代の最初のタイトル – システム側の機能を強化しながら、これまでに構築された最後のコンソールでどのように動作するかを確認します。
Digital Foundry
単一のボックス、単一のプロセッサーで複数のシステムを実行しています。それはシリコンの設計における最も重要な課題の 1 つでしたか?
ニック・ベイカー
細かいことはたくさんありました。システム全体が仮想化できることを確認し、すべてにページ テーブルがあり、IO にそれらに関連付けられたすべてのものがあることを確認する必要がありました。仮想化された割り込み…. これは、チップに統合した IP がシステム内で適切に機能することを確認する場合です。アンドリュー?
アンドリュー・グーセン
私はそれに飛び込みます。 Nick が言ったように、ハードウェアに関しては多くのエンジニアリングを行う必要がありましたが、ソフトウェアも仮想化の重要な側面でした。ソフトウェア側にはハードウェアにまで遡る多くの要件がありました。 Richard さんの質問に答えると、最初から仮想化のコンセプトが私たちの設計の多くの原動力となっていました。私たちは最初から、タイトルと同時に実行できるこの豊かな環境の概念を実現したいと考えていました。私たちにとって、Xbox 360 で学んだことを基に、タイトル (ゲーム) にできる限り影響を最小限に抑え、ゲーム側でできる限り洗練された体験を提供するこのシステムを構築することが非常に重要でした。だけでなく、その仮想マシンの境界のどちら側でも革新する必要があります。
タイトル上で実行されている部分との非常に良好な互換性を維持しながら、システム側でオペレーティング システムを更新するなどのことを行うことができます。タイトルには、同梱されている独自のオペレーティング システム全体が含まれているため、タイトルとの逆互換性が損なわれることはありません。ゲーム。逆に、タイトル面でも大幅な革新が可能になります。このアーキテクチャを例に挙げると、SDK から SDK リリースに至るまで、CPU と GPU の両方のオペレーティング システムのメモリ マネージャーを完全に書き直すことができます。これは仮想化なしでは実現できません。それは多くの重要な領域を動かしました…ニックはページテーブルについて話しました。私たちが行った新しいことのいくつか – GPU には仮想化のためにページ テーブルの 2 つの層があります。これは実際、仮想化されて実行される GPU の最初の大規模なコンシューマー アプリケーションだと思います。私たちは、仮想化にその分離性とパフォーマンスを持たせたいと考えていました。しかし、タイトルのパフォーマンスに影響を与えることはできませんでした。
私たちは、割り込み以外のグラフィックスにオーバーヘッド コストがかからないような方法で仮想化を構築しました。中断を避けるためにできる限りのことを行うよう工夫してきました…フレームごとに 2 つだけ実行します。これを達成するには、ハードウェアとソフトウェアに大幅な変更を加える必要がありました。タイトルに 2 つのレイヤー、システムに 1 つのレイヤーを与えるハードウェア オーバーレイがあり、タイトルは完全に非同期でレンダリングでき、システム側で起こっていることに対して完全に非同期で表示されます。
システム側ではすべて Windows デスクトップ マネージャーに統合されていますが、Windows システム側のスケジューラーの速度が低下するなどの不具合があっても、タイトルは更新される可能性があります。これを促進するために、仮想化の面で非常に多くの作業を行いました。また、複数のシステムを実行することで、他の多くのシステムが駆動されたこともわかります。私たちは 8GB にしたいと考えていたため、メモリ システムに関する多くの設計も推進されました。
「例として、このアーキテクチャを使用すると、SDK から SDK リリースに至るまで、CPU と GPU の両方のオペレーティング システムのメモリ マネージャーを完全に書き直すことができます。これは仮想化なしでは実現できません。」
Digital Foundry
最初から 8GB を目標にしていたのですか?
アンドリュー・グーセン
そうですね、タイトルと同時に実行したい種類のエクスペリエンスを検討していたときに、これはかなり早い段階で決定したと思います。そして、そこに必要なメモリの量。それは私たちにとって本当に早い決断だったでしょう。
Digital Foundryの
CPU側、興味があります。たとえば 4 つの
Piledriver
コアではなく、8 つの Jaguar コアを選択したのはなぜですか?重要なのはワットあたりのパフォーマンスですか?
ニック・ベイカー
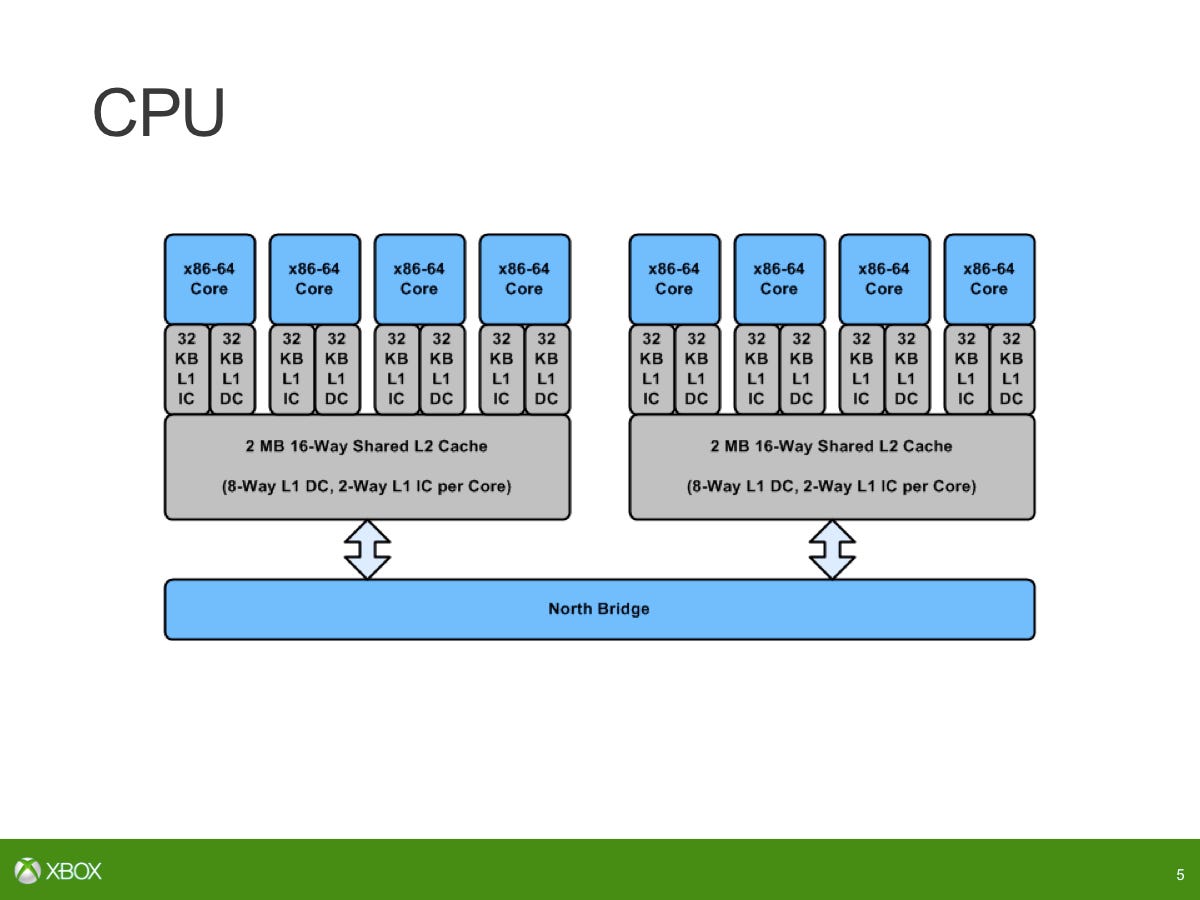
Jaguar から Piledriver への IPC ブーストの追加に伴う追加のパワーとエリア…これはコンソール用に行う正しい決定ではありません。エリアごとのパワー/パフォーマンスのスイートスポットに到達し、それをより並列的な問題にすることができます。それがすべてなのです。タイトルとオペレーティング システムの間でコアをどのように分割するかは、その点でも同様に機能します。
Digital Foundry
それは本質的には Jaguar IP そのままですか?それともカスタマイズしたんですか?
ニック・ベイカー
Xbox One が登場するまでは 2 クラスターの Jaguar 構成は存在しなかったので、それを機能させるためにはやらなければならないことがありました。私たちは GPU と CPU の間の一貫性を高める必要があったので、それを行う必要がありました。CPU 周辺の多くのファブリックに影響を与え、Jaguar コアがどのように仮想化を実装するかを確認し、そこに微調整を加えましたが、基本的なものは何もありませんでした。 ISA や命令の追加、またはそのような命令の追加。
Digital Foundry
15 個のプロセッサーがあると話していますね。それを分解してもらえますか?
ニック・ベイカー
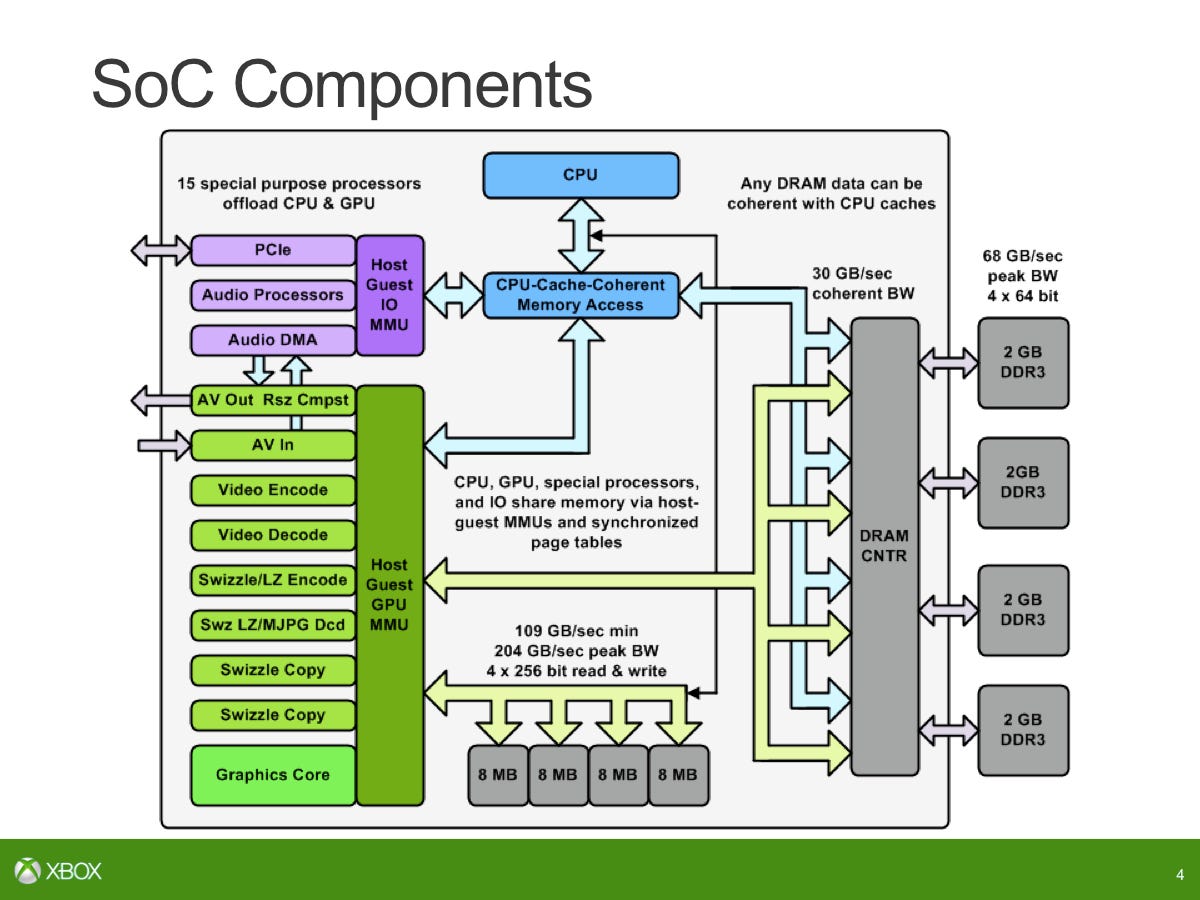
SoC 上には多くの並列エンジンがあり、その一部は CPU コアまたは DSP コアに似ています。 15 までの数え方: オーディオ ブロック内に 8 つ、ムーブ エンジンが 4 つ、ビデオ エンコードが 1 つ、ビデオ デコードが 1 つ、ビデオ コンポジター/リサイザーが 1 つあります。
オーディオブロックは完全にユニークでした。それは私たち社内で設計されました。これは、4 つの tensilica DSP コアといくつかのプログラム可能な処理エンジンに基づいています。これを、制御を実行する 1 つのコア、音声用の多数のベクトル コードを実行する 2 つのコア、および汎用 DSP 用の 1 つのコアに分割します。サンプル レート変換、フィルタリング、ミキシング、イコライゼーション、ダイナミック レンジ補正、さらに XMA オーディオ ブロックと組み合わせます。目標は、ゲーム オーディオで 512 の同時音声を実行し、Kinect の音声前処理を実行できるようにすることでした。
Digital Foundry
カスタム ハードウェアがマルチプラットフォーム ゲームで利用されないのではないかという懸念がありますが、ハードウェア アクセラレーション機能がミドルウェアに統合され、広く利用されるだろうと私は推測しています。
ニック・ベイカー
そうですね、アンドリューはミドルウェアの点について話すことができますが、これらの一部はシステムが Kinect 処理などを行うために予約されているだけです。弊社が提供するシステムサービスです。その処理の一部は Kinect 専用です。
アンドリュー・グーセン
したがって、システムとシステム予約のために私たちが設計したことの多くは、多くの作業をタイトルからシステムにオフロードすることです。これは実際にはタイトルに代わって多くの作業を行っていることに留意する必要があります。私たちはシステム予約で音声認識モードを採用していますが、他のプラットフォームではそれをコードとして持っており、開発者はそれをリンクして予算から支払う必要があります。 Kinect でも同様で、NUI [Natural User Interface] 機能のほとんどはゲーム用に無料で提供されており、ゲーム DVR も同様です。
Digital Foundry
おそらく、プロセッサーで最も誤解されているのは ESRAM と、ゲーム開発者にとっての ESRAM の意味です。これが含まれているということは、かなり早い段階で GDDR5 を除外し、DDR3 と組み合わせた ESRAM を支持したことを示唆しています。それは公平な仮定ですか?
ニック・ベイカー
はい、その通りだと思います。パフォーマンス、メモリ サイズ、電力の可能な限り最高の組み合わせを実現するという点で、GDDR5 は少し不快な場所に連れて行ってくれます。 ESRAM を使用すると、消費電力はほとんどかからず、非常に高い帯域幅が得られます。外部メモリの帯域幅を減らすことができます。これにより、消費電力も大幅に節約され、市販のメモリも安価になるため、より多くの費用をかけることができます。それがまさにその原動力です。おっしゃるとおり、大容量のメモリ、比較的低消費電力、広い帯域幅が必要な場合、それを解決する方法はそれほど多くありません。
「パフォーマンス、メモリ サイズ、電力の可能な限り最高の組み合わせを実現するという点で、GDDR5 は少し不快な場所に連れて行ってくれます。ESRAM を搭載すると電力コストはほとんどかからず、非常に高い帯域幅を得ることができます。」
の



キャプション
帰属
Digital Foundry
そして、4 ギガビット GDDR5 モジュールが発売に間に合うかどうかという実際の保証はありませんでした。それがソニーが行った賭けであり、それが功を奏したようだ。つい最近まで、PS4 SDK ドキュメントでは 4GB の RAM について言及していました。
eDRAMを搭載したIntelのHaswellが、
あなたがやっていることと最も近いものだと思います。なぜ eDRAM ではなく ESRAM を選ぶのでしょうか? Xbox 360 ではこれで大きな成功を収めました。
ニック・ベイカー
問題は、単一のダイ上で eDRAM を実行できる技術を誰が持っているかということです。
Digital Foundry
つまり、Xbox 360 のときのように娘の死を選びたくなかったのですか?
ニック・ベイカー
いいえ、先ほども言ったように、単一のプロセッサが必要でした。別の期間やテクノロジーの選択肢があれば、別のテクノロジーを使用できたかもしれませんが、その期間内の製品としては ESRAM が最良の選択でした。
Digital Foundry
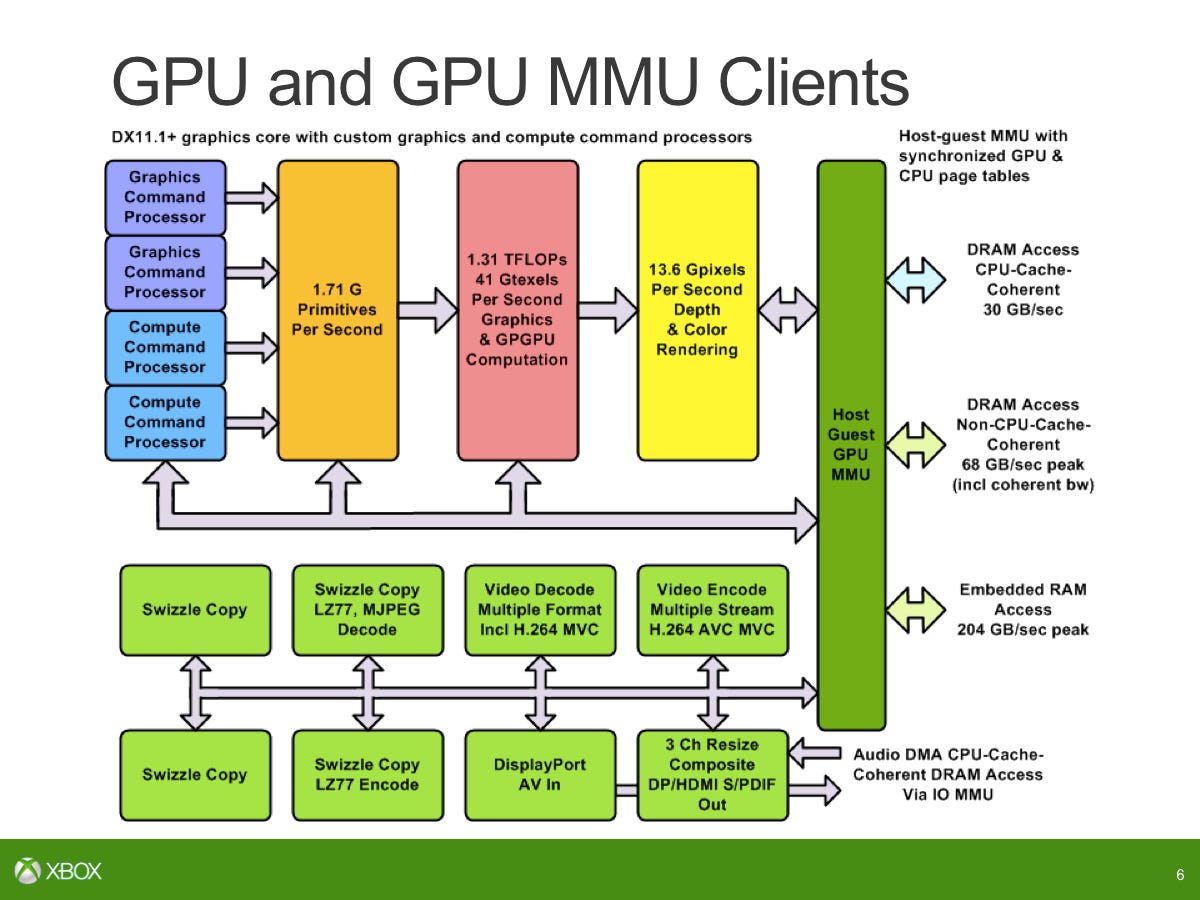
ESRAM を見ると、Hot Chips のプレゼンテーションで、8MB 領域のブロックが 4 つあることが初めて明らかになりました。それはどのように機能するのでしょうか?
ニック・ベイカー
まず最初に、GPU に ESRAM とメイン RAM を同時に使用できるかどうかという疑問があります。実際には、ESRAM と DDR3 は合計 8 つのメモリ コントローラを構成していると考えることができるため、メモリ コントローラは 4 つあることを指摘します。 DDR3 に接続される外部メモリ コントローラー (64 ビット) と、ESRAM に接続される 256 ビットの内部メモリ コントローラーが 4 つあります。これらはすべてクロスバーを介して接続されているため、実際には、DRAM と ESRAM に同時に直接アクセスできることになります。
デジタルファウンドリ
も同時に?なぜなら、帯域幅を追加することになり、現実のシナリオではこれを行うことはできないという多くの論争があるからです。
ニック・ベイカー
そのインターフェイス上では、ESRAM への各レーンは 256 ビットで、各方向で合計 1024 ビットになります。 1024 ビットの書き込みでは最大 109GB/s が得られ、その後、別の読み取りパスが再びピーク時に実行され、109GB/s が得られます。外部メモリに対して行うのと同じ種類の計算を行う場合、ESRAM の同等の帯域幅はどれくらいになりますか? DDR3 では、インターフェイス上のビット数に速度を掛けると、68GB が得られます。 /秒。 ESRAM では 218GB/s に相当します。ただし、メイン メモリと同様に、長期間にわたってこれを達成できることはまれであるため、通常、外部メモリ インターフェイスは 70 ~ 80% の効率で実行されます。
ESRAM についても同様の議論があります。Hot Chips で発表された 204GB/s という数値は、ESRAM 周辺のロジックの既知の制限を考慮に入れています。絶対にすべてのサイクルで書き込みを維持することはできません。書き込みでは時折バブル (デッド サイクル) が挿入されることが知られています…8 サイクルに 1 サイクルがバブルであるため、ESRAM 上で実際に達成できる生のピークとして合計 204GB/s が得られます。アプリケーションから何が達成できるかというと、ESRAM の測定値は約 140 ~ 150 GB/秒です。それが実際に実行されているコードです。それは診断やシミュレーションのケースなどではありません。これは、その帯域幅で実行されている実際のコードです。これを外部メモリに追加すると、同様の条件でおそらく 50 ~ 55 GB/s が達成され、これら 2 つを合計すると、メイン メモリと内部メモリ全体で 200 GB/s 程度になると言えます。
1 つ指摘しておきたいのは、8MB レーンが 4 つあることです。ただし、これらの各レーン内の連続した 8MB のメモリ チャンクではありません。各レーンでは、その 8MB が 8 つのモジュールに分割されます。これは、メモリ内で実際に読み取りと書き込みの帯域幅を同時に確保できるかどうかに対処する必要があります。はい、実際には ESRAM 全体を構成する個別のブロックがもっとたくさんあるので、それらのブロックと並行して通信できます。もちろん、同じ領域に何度も何度もアクセスした場合、分散することはありません。実際のテストでピークの 204GB/s ではなく 140 ~ 150GB/s が得られる理由の 1 つは、8MB メモリの 4 つのチャンクだけではないということです。それはそれよりもはるかに複雑で、それらを同時に使用するパターンによって異なります。これにより、読み取りと書き込みを同時に行うことができます。メインメモリに読み書き帯域幅を追加するだけでなく、読み書き帯域幅も追加できます。それは私たちが一掃したいと思っていた誤解の 1 つにすぎません。
アンドリュー・グーセン
読み取りのみを実行している場合は 109GB/s に制限され、書き込みのみを実行している場合は 109GB/s に制限されます。これを克服するには、読み取りと書き込みを組み合わせる必要がありますが、レンダー ターゲットやデプス バッファーなど、通常 ESRAM 内にあるものを見ようとすると、本質的に大量の読み取りが発生します。 -modified 書き込みがブレンド内で実行され、深度バッファーが更新されます。これらは ESRAM に固定するのが自然であり、同時読み取り/書き込みを利用するのが自然です。
Digital Foundry
つまり、140 ~ 150GB/s が現実的な目標であり、DDR3 帯域幅を同時に統合
できるということです
か?
ニック・ベイカー
はい。それは測定されました。
「Xbox One では、システム処理のために GPU 上で控えめに 10 パーセントのタイムスライス予約が行われています。これは、Kinect の GPGPU 処理と、スナップ モードなどの同時システム コンテンツのレンダリングの両方に使用されます。」

Digital Foundry
リークされたホワイトペーパーでは、ピーク帯域幅ははるかに小さかったが、突然、[社内の Xbox One 開発ブログに基づいて] 本番シリコンでピーク帯域幅が 2 倍になったという記事を掲載しました。それは予想されていましたか?保守的だったんですか?それとも、最終プロセッサを実際に触ってみて、すごいこと、これができるということがわかりましたか?
ニック・ベイカー
開始時に仕様書を書きました。実際に実装の詳細に入る前に、シリコンを入手する前、テープアウト前にシミュレーションで実行する前に、開発者に計画する内容を提供する必要があり、ESRAM に必要な最小帯域幅は 102GB であると述べました。 /秒。それは[GPU速度の向上により] 109GB/秒になりました。最終的に、これを実装すれば、はるかに高いレベルに到達できることがロジックでわかりました。
アンドリュー・グーセン
ソフトウェアの観点から参入したかっただけです。この論争は、特に ESRAM を Xbox 360 からの eDRAM の進化と見なす場合にはかなり驚くべきものです。Xbox 360 に関して、システム メモリから得られる帯域幅と同時に eDRAM 帯域幅を取得できるかどうかについて疑問を抱く人はいません。実際、システム設計ではそれが必要でした。 eDRAM 内にあるレンダー ターゲット、カラー、深度、ステンシル バッファーの処理と同時に、システム メモリからすべての頂点バッファーとすべてのテクスチャをプルオーバーする必要がありました。
もちろん、Xbox One では、ESRAM が Xbox 360 の eDRAM と同じ自然な拡張を持ち、両方を同時に使用できる設計を採用しています。これは、eDRAM で抱えていた多くの制限を解消できるという点で、Xbox 360 の素晴らしい進化です。 Xbox 360 は開発が最も簡単なコンソール プラットフォームであり、開発者にとって eDRAM に適応するのはそれほど難しくありませんでしたが、「おいおい、レンダー ターゲット全体があれば確かにいいだろう」というところはたくさんありました。 eDRAM に存在する必要はありませんでした。そこで、Xbox One では ESRAM から DDR3 にオーバーフローする機能を備えているため、ESRAM がページ テーブルに完全に統合され、ESRAM を組み合わせて使用できるようになりました。 DDR メモリも必要になります。
場合によっては、GPU テクスチャをメモリから取得したい場合があり、Xbox 360 では、テクスチャを取得するために DDR にコピーする必要がある、いわゆる「解決パス」が必要でした。これは、ESRAM で削除したもう 1 つの制限でした。必要に応じて ESRAM からテクスチャアウトできるようになりました。私の観点からすると、これは Xbox 360 のデザインに比べて非常に進化と改善、つまり大きな改善です。率直に言って、このすべてにはちょっと驚いています。
Digital Foundry
ただし、明らかに、ESRAM は 32MB に制限されています。潜在的には、たとえば 4 つの 1080p レンダー ターゲット、ピクセルあたり 32 ビット、深度 32 ビットを検討している可能性があります。つまり、すぐに 48MB になります。ということは、一部のレンダー ターゲットは DDR3 に存在し、重要な高帯域幅のレンダー ターゲットは ESRAM に存在するように効果的に分離できるということですか?
アンドリュー・グーセン
ああ、絶対に。また、レンダー ターゲットのオーバードローがほとんどない部分を作成することもできます。たとえば、レース ゲームをしていて、空のオーバードローがほとんどない場合は、リソースのサブセットを DDR に貼り付けることができます。 ESRAM の使用率を向上させるため。 GPU では、Xbox 360 で非常に人気のある 6e4 [コンポーネントごとに 6 ビットの仮数部と 4 ビットの指数] や 7e3 HDR float 形式 [6e4 形式] などの圧縮レンダー ターゲット形式を追加しました。コンポーネント 64pp レンダー ターゲットあたり 16 ビット浮動小数点では、32 ビットを使用して同等の処理を行うことができます。そのため、ESRAM の効率と使用率を実際に最大化することに重点を置きました。
Digital Foundry
そして、ESRAM への CPU 読み取りアクセス権を持っていますよね?これは Xbox 360 eDRAM では利用できませんでした。
ニック・ベイカー
実行していますが、非常に遅いです。
Digital Foundry
ESRAM での低遅延メモリ アクセスについては、オンラインで議論が行われています。グラフィックス テクノロジについての私の理解は、レイテンシーを無視し、利用可能なコンピューティング ユニットの数にかかわらず、広範囲にわたって並列化するというものです。ここでの低レイテンシは GPU のパフォーマンスに重大な影響を与えますか?
ニック・ベイカー
あなたが正しい。 GPU はレイテンシの影響を受けにくいです。レイテンシについては特に言及していません。
API としての
Digital Foundry
DirectX は現在、非常に成熟しています。開発者はそれに関して豊富な経験を持っています。これは Xbox One にとってどの程度の利点だと思いますか? API がどれほど成熟しているかを念頭に置いて、その周りのシリコンを最適化できないでしょうか?
アンドリュー・グーセン
私たちは DX11 のデザインを多くの部分で継承しています。私たちが AMD を採用したとき、それは基本的な要件でした。私たちがプロジェクトを開始したとき、AMD はすでに非常に優れた DX11 設計を持っていました。 API が最上位にあり、大きなメリットが得られると思います。私たちは実装に関する多くのオーバーヘッドを削除するために多くの作業を行ってきました。コンソールでは、D3D API を呼び出すとコマンド バッファーに直接書き込んで GPU を更新できるようにすることができます。他の関数呼び出しを行わずに、その API 関数に直接登録されます。ソフトウェアが何層にも重なっているわけではありません。その点で私たちは多くの仕事をしました。
また、この機会を利用して、GPU 上のコマンド プロセッサを高度にカスタマイズしました。ここでも CPU パフォーマンスに焦点を当てます… コマンド プロセッサ ブロックのインターフェイスは、グラフィックスの CPU オーバーヘッドを非常に効率的にする上で非常に重要なコンポーネントです。私たちは AMD アーキテクチャをよく知っています。Xbox 360 には AMD グラフィックスが搭載されており、そこで使用されている機能が数多くありました。私たちは、開発者がオブジェクト レベルで多くの状態を事前に構築し、「これを実行する」と言うだけの、事前にコンパイルされたコマンド バッファのような機能を備えていました。私たちはこれを Xbox 360 に実装し、それをより効率的にする方法と、よりクリーンな API を実現する方法についてたくさんのアイデアを持っていました。そのため、Xbox One でその機会を利用し、カスタマイズされたコマンド プロセッサを使用してその上に拡張機能を作成しました。 D3D は D3D モデルに非常によく適合しており、これは PC 上のメインライン 3D にも統合して戻したいと考えています。この小さく、非常に低レベルで、非常に効率的なオブジェクト指向による描画 [および状態] の送信です。コマンド。
「コンピューティング ユニットの数という点で最も大きな点は、非常に注目しやすい点です。CU の数を数えて、ギガフロップスを数えて、それに基づいて勝者を宣言しましょう、という感じです。」

Digital Foundry
GPU の仕様を見ると、Microsoft が AMD Bonaire 設計を選択し、Sony が Pitcairn 設計を選択したように見えます。そして明らかに、一方が他方よりもはるかに多くの計算ユニットを搭載しています。 GPU について少し話しましょう – GPU はどの AMD ファミリに基づいていますか? 南の島、海の島、火山島?
アンドリュー・グーセン
私たちの友人たちと同じように、私たちは Sea Islands ファミリーを拠点としています。エリアのさまざまな部分にかなり多くの変更を加えました。コンピューティング ユニットの数という点で最も大きな点は、非常に注目しやすい点です。 CU の数を数えて、ギガフロップスを数えて、それに基づいて勝者を宣言しましょう、というようなものです。私の考えでは、グラフィックス カードを購入するときは仕様に従っていますか、それとも実際にベンチマークを実行しますか?まず第一に、私たちは試合を出していません。試合は見れません。ゲームを見ていると、「両者のパフォーマンスの違いは何ですか?」と言うでしょう。ゲームがベンチマークです。 Xbox One を使用して、残高の多くを確認する機会がありました。ゲーム コンソールで優れたパフォーマンスを実現するには、バランスが非常に重要です。ボトルネックの 1 つが、速度を低下させる主なボトルネックになることは望ましくありません。
真の効果的なパフォーマンスの鍵となるのはバランスです。ニックと彼のチームは Xbox One で本当に素晴らしく、システム デザインの担当者がシステムを構築してくれたので、システム上のバランスをチェックし、それに応じて微調整を加える機会が得られました。数年前にすべての分析を行い、シミュレーションを行って、ゲームの利用率がどの程度になるかを推測したとき、私たちは良い仕事をできたでしょうか?当時、私たちは正しいバランスの決定を下したでしょうか? GPU クロックを上げることは、バランスを微調整した結果です。 Xbox One 開発キットのそれぞれには、実際にはシリコン上に 14 個の CU があります。これらの CU のうち 2 つは、製造時の冗長性のために予約されています。しかし、実際に 14 CU を使用した場合、12 CU と比較してどのようなパフォーマンス上の利点が得られるでしょうか?そして、GPU クロックを上げると、どのようなパフォーマンス上の利点が得られるでしょうか?そして、私たちは実際にローンチ タイトルを確認しました – 私たちは多くのタイトルを徹底的に調べました – 14 CU への移行は、私たちが行った 6.6% のクロック アップグレードほど効果的ではないことがわかりました。 CU を 14 にするとパフォーマンスがほぼ 17% 向上するはずであることはインターネットで誰もが知っていますが、実際に測定されたゲームの観点から見ると、実際に最終的に重要なのは、クロックを上げる方がエンジニアリング上のより良い決定であったということです。パイプラインにはさまざまなボトルネックがあり、[設計のバランスが崩れていると]、必要なパフォーマンスが得られなくなる可能性があります。
ニック・ベイカー
周波数を上げると GPU 全体に影響しますが、CU を追加するとシェーダーと ALU が強化されます。
アンドリュー・グーセン
右。クロックを固定することで、ALU パフォーマンスが向上するだけでなく、頂点レート、ピクセル レートも向上し、皮肉にも ESRAM 帯域幅も増加します。ただし、パイプラインを流れるドローコールや、GPR プールから GPR を読み取るパフォーマンスなど、ボトルネック周辺の領域のパフォーマンスも向上します。GPU は非常に複雑です。パイプラインには、ALU とフェッチのパフォーマンスだけでなく、ボトルネックとなる可能性のある領域が何億も存在します。
VGleaks にアクセスすると、競合他社の内部ドキュメントがいくつかありました。実際、ソニーも私たちの意見に同意してくれました。彼らは、システムが 14 CU に対してバランスが取れていると述べました。彼らは「バランス」という言葉を使いました。実際の効率的な設計という点では、バランスが非常に重要です。追加の 4 つの CU は、追加の GPGPU 作業にとって非常に有益です。実際、私たちはそれに対して全く異なるアプローチをとりました。私たちが行った実験では、CU にもヘッドルームがあることがわかりました。バランスの観点から、必要以上に CU に関してインデックスを作成したため、CU のオーバーヘッドが発生します。私たちのタイトルは、CUの利用に関して時間の経過とともに成長する余地がありますが、彼らとそれらに戻って、彼らは追加のCUがGPGPUワークロードにとって非常に有益であると賭けています。一方、GPGPUワークロードの帯域幅を持つことが非常に重要であると私たちは言ったので、これが私たちのシステムにある非常に高いコヒーレントな読み取り帯域幅に大きな賭けをした理由の1つです。
私は実際に、これらのワークロードのために私たちよりも多くのCUを持っている競争からどのように競争をするのか、より良いパフォーマンスのコヒーレントメモリを持っていることを知りません。 Xbox 360 kinectであるGPGPUに関してはかなりの経験があると思います。GPUですべての模範的な処理を行っているため、GPGPUはXbox Oneのデザインの重要な部分です。それに基づいて、将来何をしたいかを知る。模範のようなもの…皮肉なことに模範的にはあまりaluを必要としません。これは、メモリフェッチ[GPUの遅延の隠れ]という点であなたが持っているレイテンシについてはるかに重要なので、これは私たちにとって一種の自然な進化です。特定のGPGPUワークロードにとってより重要なメモリシステムのようなものです。
Digital Foundryは、
2つの冗長コンピューティングユニットによって提供される追加の計算電力の17%にわたってGPUクロック速度の6.6%の利点を高めますが、そのシナリオでROPに縛られた可能性はありますか? 16のROPSは、競争の32との別の差別化のもう1つのポイントです。
アンドリュー・グーセン
はい、フレームの一部がROPに縛られていた可能性があります。ただし、より詳細な分析では、ROPにバインドされ、帯域幅にバインドされていない典型的なゲームコンテンツフレームの一部が一般的に非常に小さいことがわかりました。 6.6%のクロック速度ブーストが追加のCUに勝った主な理由は、頂点、三角レート、抽選発行率など、パイプラインのすべての内部部分を持ち上げたためです。
「バランスの取れた」システムの目標は、定義上、いずれの領域で一貫してボトルネックされないことです。一般に、バランスの取れたシステムを使用すると、特定のフレームのコースで単一のボトルネックがめったにありません。フレームの一部は塗りつぶされたレートにバインドでき、他はバウンドでき、他のものはメモリバインドされます。他の人は波の占有に縛られ、他の人は引き分けに縛られ、他の人は状態の変化に縛られることもあります。さらに問題を複雑にするために、GPUボトルネックは1回のドローコールのコース内で変化する可能性があります。
充填率とメモリ帯域幅の関係は、バランスが必要な場所の良い例です。メモリシステムがその充填率で実行するために必要な帯域幅を維持できない場合、高い充填率は役に立ちません。たとえば、レンダリングターゲットが32BPP [ピクセルあたりビット]で、ブレンドが無効になり、深さ/ステンシル表面がZを有効にして32BPPである典型的なゲームシナリオを考えてみましょう。描画されたピクセルごとに必要な帯域幅の12バイトの帯域幅に相当します(8バイトの書き込み、4バイトの読み取り)。 13.65GPIXELS/sのピーク充填率では、ESRAM帯域幅をほとんど飽和させる必要がある164GB/sの実際の帯域幅を追加します。この場合、たとえROPの数が2倍になったとしても、帯域幅でボトルネックされるため、効果的な充填率は変更されませんでした。言い換えれば、ターゲットシナリオの帯域幅にROPをバランスさせました。頂点とテクスチャデータにも帯域幅が必要であることに注意してください。これは、通常、DDR3から来ています。
3Dゲームシナリオの代わりに2D UIシナリオ用に設計されていた場合、この設計バランスを変更した可能性があります。 2D UIには通常、Zバッファーがないため、ピーク充填率を達成するための帯域幅の要件はしばしば少ないです。
「ゲーム開発者は、最高品質のビジュアルを可能にするように自然にインセンティブされているため、各ピクセルの品質とゲームのピクセル数との間で最も適切なトレードオフを選択します。」
の



 <a class=”thumbnail” data-caption=” ” data-inline-image-href=”https://assetsio.reedpopcdn.com/killer_instinct_004.bmp.jpg?width=690&quality=75&format=jpg&auto=webp”
<a class=”thumbnail” data-caption=” ” data-inline-image-href=”https://assetsio.reedpopcdn.com/killer_instinct_004.bmp.jpg?width=690&quality=75&format=jpg&auto=webp”
「デジタルファウンドリ:完全なXbox One Architectsインタビュー」に関するベスト動画選定!
Xbox Series X – Xbox Velocity Architecture Trailer
Why Digital Games? | Official Xbox Walkthrough



















